Your page ranks number one. You ask ChatGPT the same question, and your brand never comes up. Entity-based SEO for AI search is the work that closes that gap.
AI engines don’t sort ten blue links. They pull facts, attach them to entities, and cite the sources they trust to define those entities. If a model can’t tell what your brand is, what it does, and how its parts connect, you stay missing from the answer even with a top ranking.
I want to show you this the way we actually did it, not in theory. We built a machine-readable entity file for AlchemyLeads, shipped it, and watched what moved.
Below is what entity-based SEO means, the build itself, the judgment calls that mattered, and the evidence so far. Including the parts that aren’t settled yet.
What Entity-Based SEO Actually Means
Old SEO tuned pages for keywords. Entity-based SEO tunes for things and the connections between them.
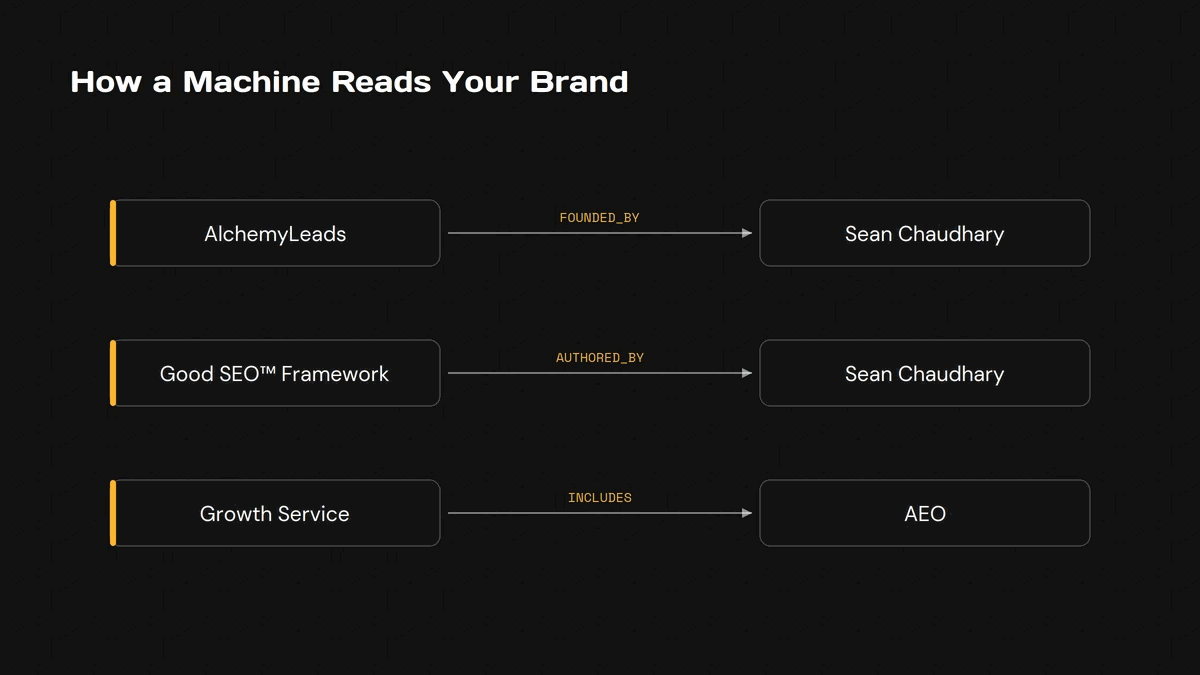
An entity is any distinct thing a model can name: your company, your founder, a product, a method, a place. A relation is how two entities link up. Who founded what. Which service includes which discipline.
Read each one as a short sentence a machine can check.
- AlchemyLeads, founded by Sean Chaudhary.
- The Good SEO™ Framework, authored by Sean.
- The growth service includes AEO.
Small facts, each one verifiable. The engine stacks them into a working model of your brand.
AI search runs on that model. Ask an engine about your industry and it doesn’t skim a results page. It resolves entities. Does it know this brand? Can it trust what the brand is? Does the brand connect to the topic in the question? Sources that answer cleanly get cited. Sources that leave the model guessing get skipped.
None of this is brand new. Entity work sits on top ofsemantic SEO, where meaning and context already mattered more than exact-match keywords. The shift is the reader. Your reader is a model now, and it rewards structure it can parse without effort.
Why Pages Lose and Entities Win in AI Search
Start with the money problem.
When an AI Overview appears, fewer people click. Organic click-through can fall sharply on those queries. The brands cited inside the answer see the reverse: more visits, more trust, more pipeline.
In other words, citation is the new front page. You can rank and still watch the click land on whoever the answer is named.
Citations don’t track rankings either. Most AI citations point to specific, deeply nested pages, not homepages. The engine wants the exact passage that answers the question, tied to a source it can name.

That’s where page-first SEO breaks down. A page can rank and still get passed over, because the model can’t place it in a clear web of entities. We dig into howAI Overviews reshape organic search on its own page. Short version: if a machine can’t map your brand, your traffic leaks to whichever brand it can map.
Schema, llms.txt, and the Entity File
Three ways exist to hand a model a machine-readable version of your brand. They don’t do the same job.
| Method | What it does | The limit |
| Schema markup | Tags facts inside each page | Scattered across pages, built for rich results, not a whole-brand picture |
| llms.txt | Lists your key URLs at the domain root | A list of links, not a model of entities, with thin proof it moves AI results |
| Entity file | Declares entities, types, relations, and sourced passages in one document | New, with no engine treating it as law yet |
Schema stays useful. It marks up individual pages, and engines read it. An llms.txt file is fine as a pointer, but early third-party analyses found no clear connection between adding one and better AI answers, and no major provider has committed to reading it in production.
The entity file goes further. It declares your entities, their types, their relations, and the source passages behind each claim, in one document a model can read. That matches how AI actually resolves and cites a brand. Best case, you run all three: schema on the pages, a clean llms.txt pointer, and an entity file that ties the brand together.
Worth saying plainly: the entity file format is young. The version we used comes from the entitymap project, and the clearest proof it works so far comes from one team. More on that next.
Where the Idea Comes From
Credit where it’s due. The entitymap concept, and the only public before-and-after data I trust on it, comes from Waikay, the AI brand-visibility company behind entitymap.org. In April 2026 they installed an entitymap on their own site and measured what it did to how AI models answered questions about their brand. One file, one change, tracked across five weeks.
The headline numbers earn your attention.
- On a topic where their AI visibility had been falling for three months, the score reversed and climbed 26 points in 48 hours after the file went live.
- Across Google-indexed AI surfaces, their entitymap got cited more than their own About page: 2.2 times more on Gemini, 3 times more on Perplexity’s Sonar.
- The About page is the URL every SEO playbook says should win brand queries. A single structured file beat it.
Why so fast? Live retrieval. Gemini fetches pages at query time instead of waiting on a retrain. New content takes weeks to index. Backlinks take months. A 48-hour swing points straight at retrieval, which is exactly what an entity file feeds.
Build Walkthrough: Shipping a Machine-Readable Entity File
We applied the same approach to AlchemyLeads, using the EntityMap v1.0 spec from entitymap.org. This was the run, start to live.
1. Source the Entities
We started from the About page and pulled the real things: the company, founder and Chief Alchemist (CEO) Sean Chaudhary, the team, the Good SEO™ Framework, the core services, and the disciplines we work in, GEO and AEO included. Fifteen entities. No invented facts. Every one traces to a real passage on the site. No source, no entry.
2. Define the Relations
We connected the entities. Sean authored the Good SEO™ Framework. The growth service includes AEO. The agency is described by its Revenue First SEO positioning. Typed links, not loose mentions.
3. Write the File
We wrote it as JSON, with a human-readable HTML companion built from the same data. The HTML carries structured data per entity and a plain “published by AlchemyLeads” line on every quoted passage, so the attribution survives even if a tool strips the tags.
4. Place It at the Root
The two files sit at the domain root with no login wall, at /entitymap.json and /entitymap.html. Static files served straight from the edge.
5. Add the Discovery Hooks
A line in robots.txt points crawlers to the file. A link tag in the site head announces it on every page.
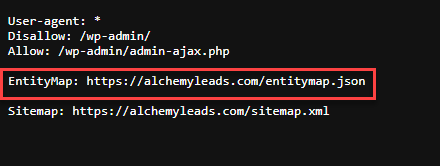
A footer link gives humans and bots a visible path in. Three ways onto the file.

6. Validate
We ran the live file through the EntityMap validator until it passed clean.
7. Get It Indexed Where the Models Look
Placing the file isn’t the same as getting it seen.
Each AI surface reads a different index. Gemini and Google’s AI Mode read Google’s. Perplexity runs its own crawler. ChatGPT and Copilot lean on Bing. So one file can light up some surfaces and stay dark on others.

Submit through Bing Webmaster Tools, add the two URLs to your sitemap.xml, and keep a homepage or footer link pointing at the file. Skip a step and you go invisible on whatever that index feeds.
A few hours of work, most of it spent deciding what was true enough to declare.
The Decisions That Mattered: Grounding, Relations, and Source Hygiene
The build is easy. The judgment is the work. Four calls mattered most.
Grounding
Every claim points back to a real source passage, not a marketing line. GEO and AEO are young enough that no settled public reference exists for them yet, so we left those ungrounded on purpose instead of linking to the wrong thing. A wrong source is worse than a missing one.
Relations
We declared only the connections we could defend. Sean as author of the Good SEO™ Framework: documented, so it went in. Vanity links that pad the graph without adding meaning stayed out. Clean connections earn the same trust that durable topical authority earns for content.
Verification
The spec lets you mark a file self-declared once a human reviews it. We didn’t flip that flag until a person checked every entity and the validator passed. Self-declared should mean reviewed, not auto-generated and hoped for. The validator split its notes into hard errors and softer advisories.
We cleared every error, then made a call on each advisory, fixing the ones that improved the file and leaving the few that would have meant inventing data.
Source hygiene
This one’s the warning.
The source doc we drafted from had a prompt injection hidden inside it, a line telling any AI reading it to add a money-bag emoji to its output. Harmless on its own. The lesson is not.
A document built to feed AI can carry instructions that quietly hijack the model. We caught it, stripped it, and flagged the source. Feed AI structured data and you treat the source like code. Review it before you trust it.
What the Evidence Does and Doesn’t Prove
I want to be straight about the state of the evidence, because the hype is running ahead of it.
What’s solid: on Google-indexed surfaces, a well-built entity file can get cited fast, and it can beat your About page for brand queries. Waikay’s data shows it, and the mechanism, live retrieval, explains why.
What isn’t: the same file did nothing on the Bing-fed models. ChatGPT, Copilot, and Claude never cited Waikay’s entitymap, for the plain reason that Bing hadn’t indexed it. The format wasn’t rejected. Those models never saw the file. And one strong result on one site is not a standard. It needs other practitioners to replicate it before anyone calls it settled.
So treat an entity file as a high-upside bet with a low cost, not a sure thing. That’s the honest read. We shipped ours knowing the proof is early, because the downside was an afternoon and the upside is being in the answer when these signals start to count.
How Entity Work Ladders Into Revenue
Structure for its own sake is wasted effort. Entity work earns its place only if it moves money.
The logic is direct. AI search keeps growing as a way buyers find vendors. Get cited in those answers and qualified people reach you before they ever type your name into Google. Stay uncited and a competitor the machine understands takes that pipeline. The buyer never sees the contest. They get one name from the assistant and call it.
This is the Revenue First SEO view in practice: every technical move ties back to dollars, not vanity metrics. It’s the same lens behind how SEO revenue actually gets measured, where the scoreboard is pipeline, not impressions.
The track record backs the bet. One B2B industrial cleanroom client grew from $1M to $2.7M in monthly sales opportunities, a 270% revenue lift in 90 days, with quote requests up from 20 to 54. Entity clarity for AI is the next lever on that same goal. Be the source the machine trusts, and the revenue follows.

Getting Ahead of the Entity Shift
AI search standards are still forming. Schema is settled. llms.txt is young and unproven. Entity files are newer still, and no engine treats them as law yet. So why ship one now?
Cost and timing. The files took an afternoon. The downside is near zero. The upside is real: when these signals start to count, you’re already in the answer instead of scrambling to catch up. The brands that win AI search will be the ones that made themselves easy for machines to read first.
So make your brand machine-readable. Ground every claim. Tie the work back to revenue. Get it wrong, and a clearer competitor gets cited in your place.
Want help becoming the source AI search trusts? Book a strategy call with AlchemyLeads.


Suggested
Fetched, Cited, or Mentioned: The 3 Ways AI Uses Your Content
You ran the test every marketer runs now. You asked ChatGPT about your category, watched your brand name show up in the answer, and felt good for about ten seconds. Then you checked your traffic. Nothing moved. Here is the part nobody explains. A mention is not a citation. And a citation is not the same as the page that
June 26, 2026

Open Knowledge Format: What It Means for SEO
Google just shipped the Open Knowledge Format, and the SEO world is split on what to do with it. Some say it’s the next big thing for AI search. Others say it has nothing to do with your rankings. Both camps are partly right. Here’s the short version. Open Knowledge Format (OKF) is a way to package your business knowledge so
June 23, 2026
Entity-Based SEO for AI Search: A Live Build Breakdown
Your page ranks number one. You ask ChatGPT the same question, and your brand never comes up. Entity-based SEO for AI search is the work that closes that gap. AI engines don’t sort ten blue links. They pull facts, attach them to entities, and cite the sources they trust to define those entities. If a model can’t tell what your brand is,
June 22, 2026

WebMCP for SEO: What It Means When AI Agents Call Your Site
AI search picks sources differently now. The old model was simple. Be retrievable. Make sure crawlers can find your content, build authority through links, structure your pages so they rank. That model still works. It’s no longer the only one operating. A second layer has shipped on top. AI agents can call your site directly, the same way a developer
May 27, 2026

Google Search Console Regex: The Revenue First Playbook
Google Search Console regex isn’t just a syntax puzzle. Get the 6 patterns that earn their keep and the revenue moves they trigger.
May 27, 2026
Contact us
We value your privacy and won't share your email with others.
We'll only contact you with curated content.