An N-gram is a contiguous sequence of n items, usually words, but also characters, syllables, phonemes, or even DNA base pairs, taken from a piece of text or speech. The “n” is just how many items are in the sequence: one item is a unigram, two is a bigram, three is a trigram, and so on. N-grams are a foundational technique in natural language processing (NLP) and corpus linguistics, used for spelling correction, text prediction, machine translation, text mining, and language modeling, because counting which sequences appear, and how often, lets a system estimate the probability of what word comes next. For the sentence “Follow good SEO practices,” the bigrams are “Follow good,” “good SEO,” and “SEO practices.”
This guide covers what N-grams are, the main types with worked examples, how they’re used in NLP, and how they relate to modern models like BERT.
Types of N-Grams (With Examples)
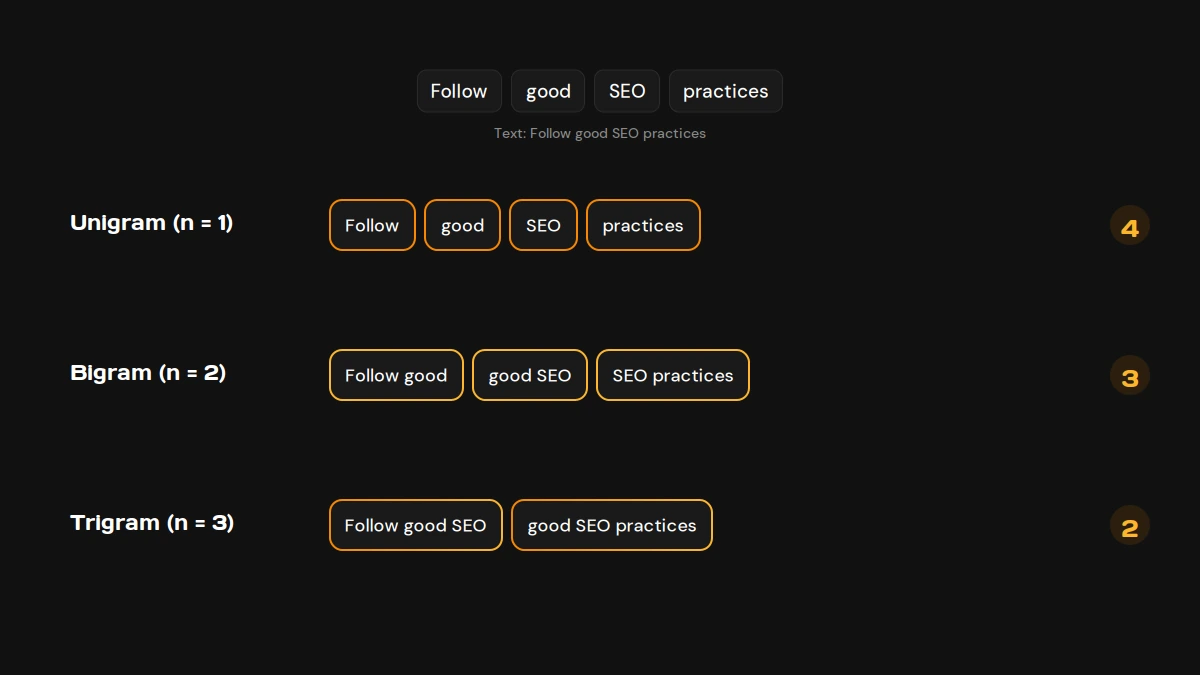
“N” is a positive integer, 1, 2, 3, 4, and so on, and the name of the n-gram changes with it. Using the same sample text, Text = “Follow good SEO practices”, here is how each one breaks down:
Unigram (n = 1)
A unigram is a single word, the most basic unit of text. Unigrams for the sample: (“Follow,” “good,” “SEO,” “practices”). You take one word at a time.
Bigram (n = 2)
A bigram is two adjacent words. Bigrams for the sample: (“Follow good,” “good SEO,” “SEO practices”). You take two words at a time, sliding one word forward each step.
Trigram (n = 3)
A trigram is three adjacent words. Trigrams for the sample: (“Follow good SEO,” “good SEO practices”).
4-Grams and Higher
N isn’t capped at three, you can have 4-grams, 5-grams, 6-grams, and beyond. For Text = “Always work with the best SEO agency,” the 4-grams are: (“Always work with the,” “work with the best,” “with the best SEO,” “the best SEO agency”). Higher-order n-grams capture more context but need much more data to estimate reliably.
What Is an N-Gram in Corpus Linguistics?
In corpus linguistics, an N-gram is a sequence of tokens (typically words) drawn from a corpus, a bigram is two tokens, a trigram three, and so on. These multi-word sequences are also called MWEs, or multiword expressions. Building a list of the most frequently occurring n-grams reveals patterns of language use that aren’t obvious through other methods, which is useful for analyzing real usage and for helping learners memorize common phrases as complete units. The mathematics behind n-gram frequency and probability is covered in depth in Stanford’s Speech and Language Processing (Jurafsky & Martin), Chapter 3, the standard reference on n-gram language models.
N-Grams in NLP
In NLP, n-grams are sequences of n words used to capture context and the relationships between words. You generate them by sliding a window of n words across a corpus, then analyze how often each sequence appears to find common word patterns and train models for tasks like text classification and sentiment analysis. N-grams underpin classic statistical language models used in information retrieval and remain a useful baseline even alongside modern neural methods.
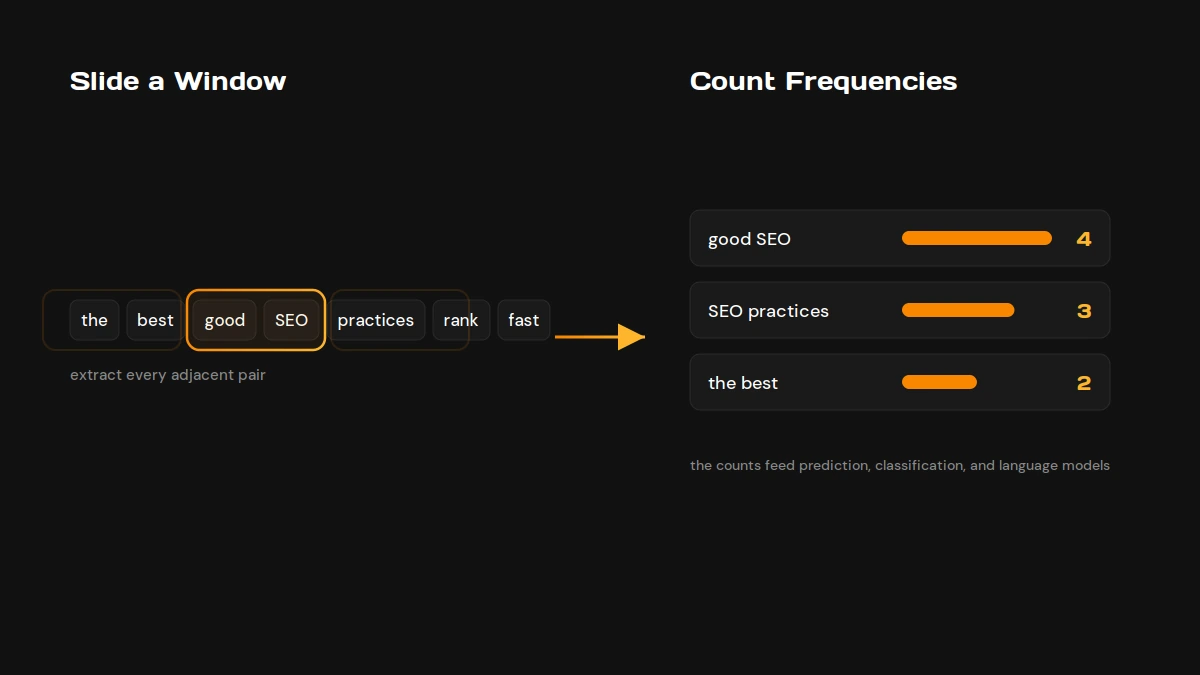
Why N-Grams Matter in NLP
- Language modeling: n-grams estimate the probability of word sequences, which powers speech recognition, machine translation, and auto-complete.
- Text prediction: the most frequent n-grams help predict the next word in a sequence, useful for text generation and autocomplete.
- Information retrieval: n-grams help match and rank documents to return relevant results.
- Context and semantics: n-grams capture meaning within a sequence of words, making language easier to interpret.
Key Use Cases of N-Grams in NLP
Machine Translation
N-grams help a system read a phrase in context. In “She went to the bank to withdraw money,” an n-gram model can use surrounding words like “withdraw money” to infer that “the bank” means a financial institution rather than a riverbank, improving translation quality.
Speech Recognition
N-grams help speech systems pick the right words from sound. Recognizing “ice cream,” for example, is easier because the model knows “cream” commonly follows “ice.”
Text Classification
N-grams turn text into features for classification. Classifying the review “The movie was absolutely fantastic and enjoyable” into positive vs. negative, the model learns that bigrams like “absolutely fantastic” and “and enjoyable” are associated with positive sentiment, then applies that to new reviews.
Predictive Text Input
Smartphone keyboards use n-grams to suggest the next word from context. After “I want to buy milk and…,” the system might suggest “bread,” “eggs,” or “groceries.”
Named Entity Recognition (NER)
N-grams help NER systems identify and classify entities like names, locations, organizations, and dates by recognizing characteristic word sequences.
Topic Modeling
N-grams surface recurring phrases, “health & wellness,” “artificial intelligence,” “climate change”, so an algorithm can cluster documents by theme and categorize them automatically.
Search Engine Algorithms
Search engines use n-grams to break queries and documents into smaller sequences for matching. A search for “best CBD marketing agency in Los Angeles” is split into sequences like “best CBD,” “CBD marketing,” “marketing agency,” and “Los Angeles,” which the engine matches against indexed content. Understanding how engines decompose queries is also central to modern query fan-out and GEO/AI SEO, where a single prompt is expanded into many sub-queries.
N-Gram Language Modeling
A language model assigns probabilities to sequences of words, and n-grams are the classic way to build one. There are two broad approaches: statistical language modeling (n-gram based) and neural language modeling.
Statistical (N-Gram) Language Models
A statistical model predicts the probability of a word from the words before it. Key ideas:
- N-grams: in a bigram model, a word’s probability depends on the single previous word; a trigram model uses the previous two.
- Probability estimation: the likelihood of a sequence is the product of each word’s conditional probability given the previous N-1 words.
- Smoothing: techniques like Laplace (add-one), Good-Turing, and Kneser-Ney handle the “zero probability” problem for n-grams never seen in training.
In short: a unigram model treats each word independently, a bigram model conditions on the previous word, a trigram model on the previous two, and higher-order models use more context but need much more data to estimate accurately.
A Simple N-Gram Example in Python (NLTK)
You can generate n-grams in a few lines with NLTK. This example tokenizes a sentence, builds bigrams, and counts their frequencies:
| import nltk
from nltk.util import ngrams from collections import Counter text = “This is a simple example to demonstrate N-gram language modeling.” tokens = nltk.word_tokenize(text.lower()) # Generate bigrams (n = 2) bigrams = list(ngrams(tokens, 2)) # Count how often each bigram appears bigram_freqs = Counter(bigrams) print(bigram_freqs.most_common()) |
Change the second argument to ngrams() to 1, 3, or 4 to produce unigrams, trigrams, or 4-grams. From the frequency counts you can estimate bigram probabilities (and apply smoothing) to build a basic statistical language model.
Beyond N-Grams: Neural Models, BERT, and RAG
N-grams are powerful but limited, they only model local patterns within a fixed window and struggle with long-range context. Modern NLP addresses that with neural language models that represent words as vectors (embeddings like Word2Vec, GloVe, or FastText) and learn patterns with architectures such as RNNs, LSTMs, and Transformers. Two approaches are worth knowing in relation to n-grams:
- BERT (Bidirectional Encoder Representations from Transformers): unlike an n-gram model that reads left-to-right within a window, BERT reads context from both directions at once using self-attention, so it captures sentence-level meaning that simple n-gram counts can’t.
- RAG (Retrieval-Augmented Generation):RAG pairs a retriever that pulls relevant documents from a corpus with a generator that writes a response grounded in them, drawing on external knowledge rather than only local word patterns.

The takeaway: n-grams remain a fast, interpretable baseline and a building block for understanding language modeling, while neural models like BERT and RAG handle the deeper context that n-grams alone can’t.
N-Grams FAQs
What are n-grams?
An n-gram is a contiguous sequence of n items, usually words, but also characters or syllables, taken from text or speech. One item is a unigram, two a bigram, three a trigram. N-grams are used in NLP and corpus linguistics for tasks like text prediction, machine translation, and language modeling.
What is an example of an n-gram?
For the sentence “Follow good SEO practices,” the unigrams are (“Follow,” “good,” “SEO,” “practices”), the bigrams are (“Follow good,” “good SEO,” “SEO practices”), and the trigrams are (“Follow good SEO,” “good SEO practices”).
What is the difference between a unigram, bigram, and trigram?
They differ only in n: a unigram is one word, a bigram is two adjacent words, and a trigram is three adjacent words. Higher n captures more context but requires more data to estimate reliably.
What is an n-gram model?
An n-gram model is a statistical language model that predicts the probability of a word based on the previous N-1 words, a bigram model uses the previous one word, a trigram model the previous two. The probability of a sequence is the product of these conditional probabilities, often adjusted with smoothing.
How are n-grams used in SEO and search?
Search engines break queries and documents into n-grams to match and rank content. A query like “best CBD marketing agency in Los Angeles” is split into sequences such as “CBD marketing” and “marketing agency,” which the engine matches against indexed pages.
N-Grams: Wrapping Up
N-grams are one of the simplest and most useful ideas in NLP: count which sequences of words appear, and you can predict, classify, translate, and retrieve text. They’re the foundation of statistical language modeling and a stepping stone to understanding the neural models, BERT, RAG, and the LLMs behind modern search, that build on the same goal of modeling language in context.
Want your content optimized for how modern search engines actually parse language? Explore our SEO services or read our guide to query fan-out and GEO/AI SEO.


Suggested

Agentic Resource Discovery: A Practical Walkthrough
Agentic resource discovery is the new standard that tells AI agents what your website can do for them. Most sites have no answer yet. They are invisible to the agents that will soon book, buy, and research for real customers. Here is the problem. Search is moving from people typing queries to agents acting on their behalf. If an agent
July 6, 2026
How to Solve the AI Search Attribution Funnel
Your AI search work is paying off. People are finding you in ChatGPT and Perplexity, your brand shows up in the answers, and demand feels warmer than it did last year. Then you open your analytics. The channel that grew is “Direct.” The report says AI sent you almost nothing. That gap is not a traffic problem. It is an
July 2, 2026
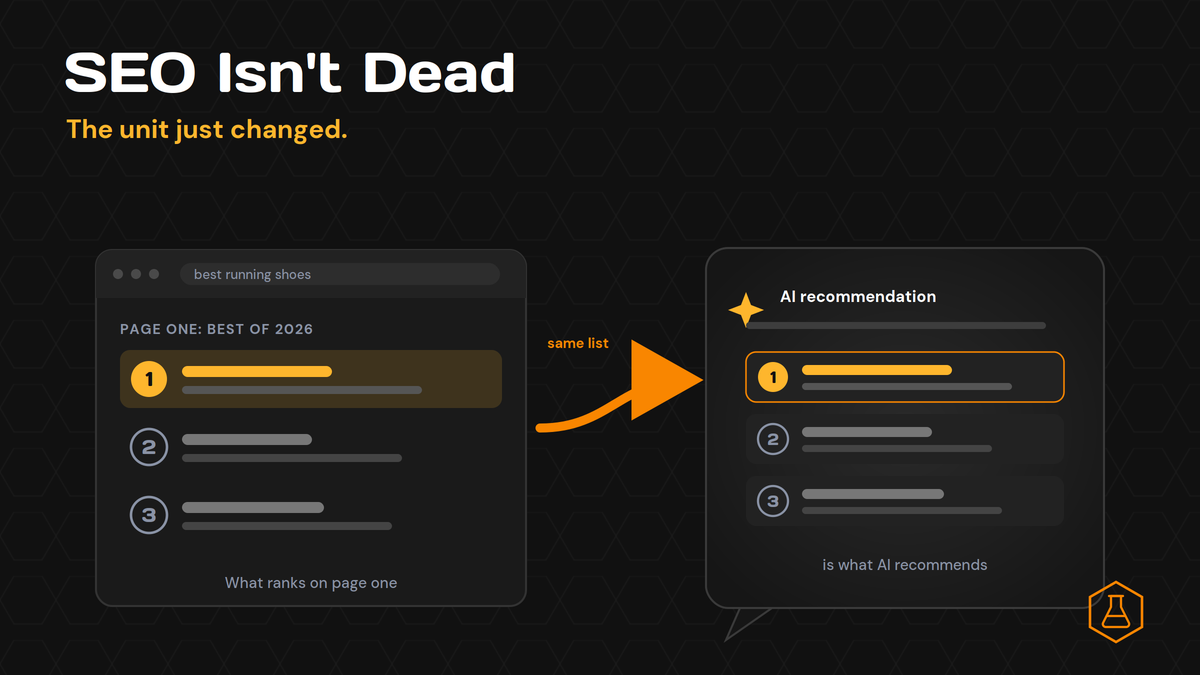
SEO Isn’t Dead. The Unit Just Changed.
Every quarter someone declares SEO dead. This year AI search is holding the knife. The logic sounds clean: if ChatGPT and Perplexity answer the question, nobody clicks a blue link, so why rank at all? We wanted a real answer, not a hot take. So we ran the test. We sent 8 buyer-style “best tool” questions through Perplexity and logged
June 29, 2026
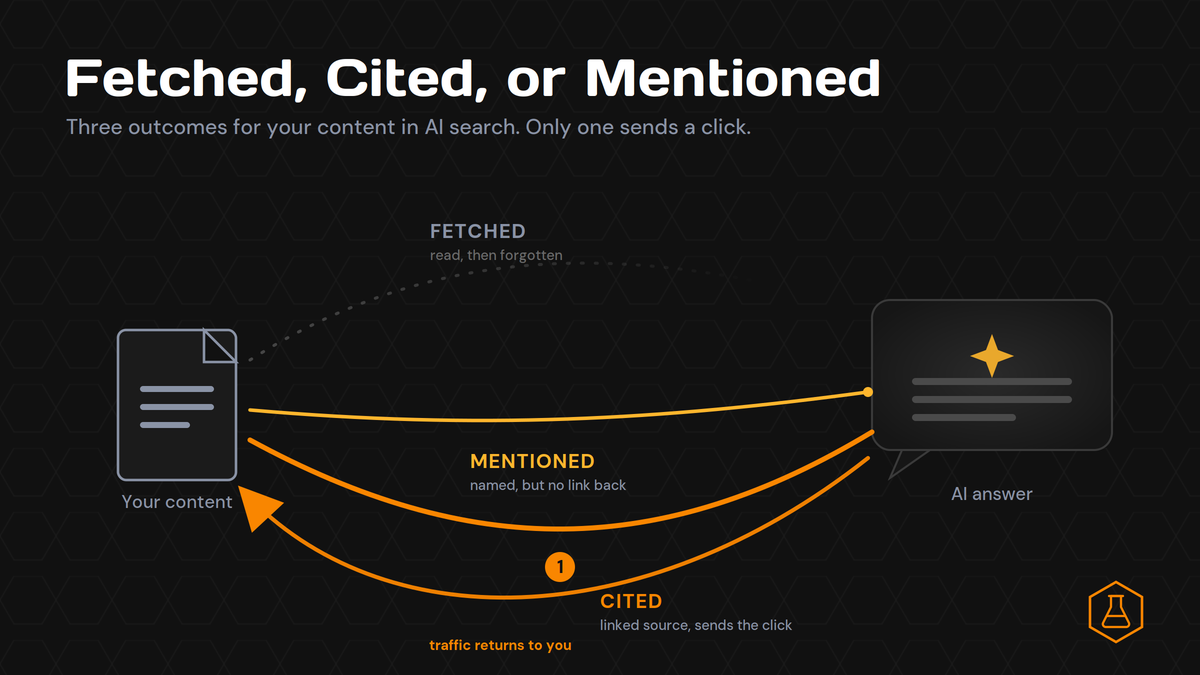
Fetched, Cited, or Mentioned: The 3 Ways AI Uses Your Content
You ran the test every marketer runs now. You asked ChatGPT about your category, watched your brand name show up in the answer, and felt good for about ten seconds. Then you checked your traffic. Nothing moved. Here is the part nobody explains. A mention is not a citation. And a citation is not the same as the page that
June 26, 2026

Open Knowledge Format: What It Means for SEO
Google just shipped the Open Knowledge Format, and the SEO world is split on what to do with it. Some say it’s the next big thing for AI search. Others say it has nothing to do with your rankings. Both camps are partly right. Here’s the short version. Open Knowledge Format (OKF) is a way to package your business knowledge so
June 23, 2026
Contact us
We value your privacy and won't share your email with others.
We'll only contact you with curated content.