The retrieve-once-then-generate model that defined the first wave of AI search is over. Every major AI search platform has moved on. Google AI Mode, ChatGPT Search, Perplexity Pro Search, Claude with Computer Use, and the Microsoft Copilot agents all run a different architecture now.
They plan. They route between tools. They retrieve, read, then retrieve again. They grade their own first drafts and decide whether to go back for more. The pattern has a name: agentic RAG, and it’s the new default.
If your AI search visibility strategy is still optimized for single-shot retrieval, you’re optimizing for a system that no longer exists. Worse, the traditional reverse-engineering playbook (rank checking, citation counting, prompt-by-prompt sampling) only sees the last stage of a multi-stage pipeline. Everything that happens upstream is a black box.
This piece walks through what agentic RAG is, why it broke the old model, what your content has to win at now, and how to actually budget for it.
What Is Agentic RAG?
RAG, or retrieval-augmented generation, is the pipeline that lets a language model answer questions using information it didn’t memorize. Query enters, retriever pulls relevant passages from an index, model writes the answer with citations.
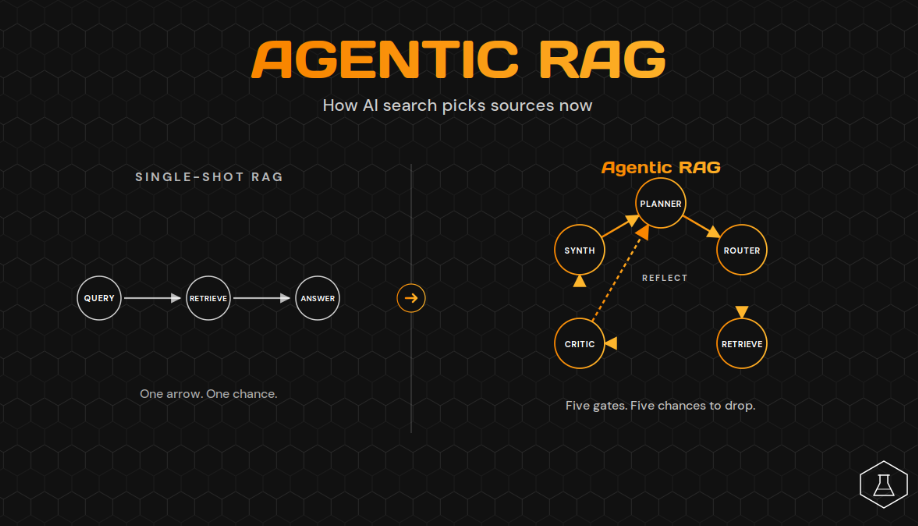
Agentic RAG adds four behaviors that classic RAG lacked. The agent plans the research before retrieving. It picks the right retrieval tool for each sub-question. It iterates, retrieving again based on what the first results revealed. And it critiques its own draft answer, going back for more if the evidence isn’t sufficient.
The shift is structural. A single user query now triggers anywhere from a handful to dozens of internal sub-retrievals. The agent orchestrates them, evaluates the intermediate results, and only synthesizes a final answer once the system has decided the evidence base is good enough.
Think of classic RAG as an assembly line. Question goes in one end, answer comes out the other. Agentic RAG is a loop with five stops, and your content has to survive all five to get cited.
The Four Properties That Make RAG Agentic
The word “agentic” gets used loosely. A system needs all four of these behaviors to qualify.
| Property | What It Does | Where You See It |
| Planning | Decomposes the user query into a research plan with sub-queries and tool assignments before any retrieval runs | Google AI Mode’s query fan-out; ChatGPT Deep Research’s visible plan |
| Tool Use | Picks the right retrieval surface per sub-query: vector search, BM25, structured API, code interpreter, live web fetch, MCP server | “Function calling” in every frontier model; Claude’s Computer Use |
| Iteration | Retrieves, reads, then retrieves again, following bridge entities the first pass surfaced | Multi-hop research in Perplexity Pro Search and ChatGPT Deep Research |
| Reflection | Grades the draft answer against the evidence and decides whether to ship or re-query | Self-RAG and self-critique patterns across all major platforms |
Two of those properties have foundational research papers attached: ReAct (Yao et al., 2022) named the planning-plus-reasoning interleave, and Self-RAG (Asai et al., 2023) named the reflection mechanic. Anthropic’s Building Effective Agents essay frames agents as systems where the language model directs its own process and tool use to accomplish a task. Control over the work, not just the output.
The terminology varies by vendor. The four properties don’t. If a platform doesn’t do all four, it’s not running agentic RAG yet, it’s running a fan-out variant of the old model.
Why Single-Shot RAG Stopped Working
The old pipeline had four failure modes that the new architecture explicitly fixes.
| Failure Mode | What Broke | The Fix |
| Compound questions | A query like “how does a 1031 exchange interact with a SEP IRA” needs five retrievals, not one. Single-shot RAG lands on documents about one or the other, and the synthesis bridges retrievals it never made | Planning decomposes the question into sub-queries before retrieval |
| Bad first pull | If the initial retrieval misses the canonical source, the model leans on parametric knowledge. Hallucinations cascade | Iteration retrieves again based on what the first pass revealed |
| No routing | Vector search is right for some sub-questions and wrong for others. A live price needs a structured API call, not a passage search | Tool use picks the appropriate retrieval surface per sub-query |
| No critique | The model ships whatever it generates. No check, no second pass | Reflection grades the draft and triggers a re-query if needed |
The shift from single-shot to agentic isn’t a refinement. It’s a different architecture. A piece of content that ranked well under the old pipeline can be invisible under the new one. The gatekeepers your content has to clear have multiplied.
The Five-Stage Gauntlet Your Content Now Faces
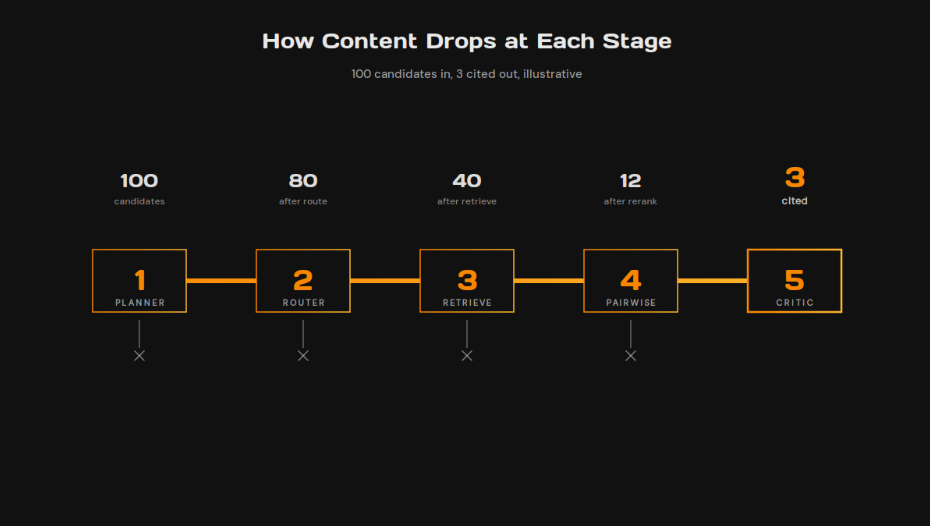
Here is the part that matters for your content strategy. Under agentic RAG, your content doesn’t compete in one moment of judgment, the way a SERP ranking decision works. It competes in five. Each stage drops content. Each stage runs on different signals. Most teams optimize for one or two and lose the rest by default.
| Stage | What It Does | What Drops Out |
| 1. Planner | Decides what sub-queries the system runs to answer the user’s question | Content on topics the planner doesn’t generate sub-queries for. If your category falls outside the fan-out, you’re not in the consideration set at all |
| 2. Router | Decides which retrieval tool fits each sub-query | Content that lives only as prose pages when the router routes to a structured API, a calculator, or a domain-specific MCP server. Tool surface absence eliminates you |
| 3. Retrieval | Runs the actual retrieval (vector, BM25, structured) and returns candidates | Content that doesn’t score well on the relevant retrieval signal. Passage-level coherence, structured data, fresh authority |
| 4. Pairwise re-rank | The agent compares surviving candidates head-to-head and keeps the winners | Content that loses a side-by-side reading test against a competitor’s page. Tightness, specificity, and clarity decide the comparison |
| 5. Critic | Grades the draft answer for sufficiency, contradiction, freshness, source diversity | Content the critic flags as redundant, off-topic, or weaker than another surviving source. The critic is the gatekeeper nobody talks about, and it cuts the most |
The implication is operational. You used to win or lose on rankings. Now you win or lose on five separate gates, and the visible signals (clicks, impressions, ranking position) only tell you about the last stage. Stages 1, 2, and 3 happen upstream, in the dark.
The AI Overviews and SGE shift to organic search is the live, visible version of this gauntlet. The AI engines running it have already absorbed agentic RAG. The teams that ranked in the SGE era and are now invisible in AI Mode usually lost at one of the upstream stages, not the SERP.
What This Means for Your Content (and Your Budget)
Surviving five stages takes a different kind of content investment than ranking did.
You need topical breadth so the planner generates sub-queries that touch your category. You need tool-surface presence (structured data, APIs where relevant, schema-marked entities) so the router considers you. You need passage-level depth so retrieval scores you. You need specificity and first-hand expertise so the pairwise re-rank picks you over a competitor. And you need source diversity so the critic doesn’t flag you as redundant.
None of that fits the standard content-per-piece budget that most marketing teams negotiated five years ago. The old budget assumed one writer producing one polished blog post per week, scoped to rank for one keyword. The new budget needs to fund interviews, original research, structured data engineering, schema markup, third-party authority building, and content tuned for passage-level retrieval.
Two outcomes follow when the budget reframe doesn’t happen. One, the content team gets handed agentic RAG visibility as additional scope on top of the existing calendar. Citation share stays flat. The work to win five stages is bigger than the headcount allowed for one. Two, leadership notices the AI search visibility gap, hires a vendor pitching “GEO services,” and gets a re-packaged version of the same content motion at a markup.
Revenue First SEO under a no-retainer model was scoped for exactly this conversation: name agentic search visibility as its own budget line, fund the workstreams that win each of the five stages, and report against citation share, not rankings.
The topical infrastructure question runs parallel. Topical maps supply the breadth the planner needs to generate sub-queries against your category. Without that scaffold, you’re not winning Stage 1.
How AlchemyLeads Helps Clients Win the Five Stages
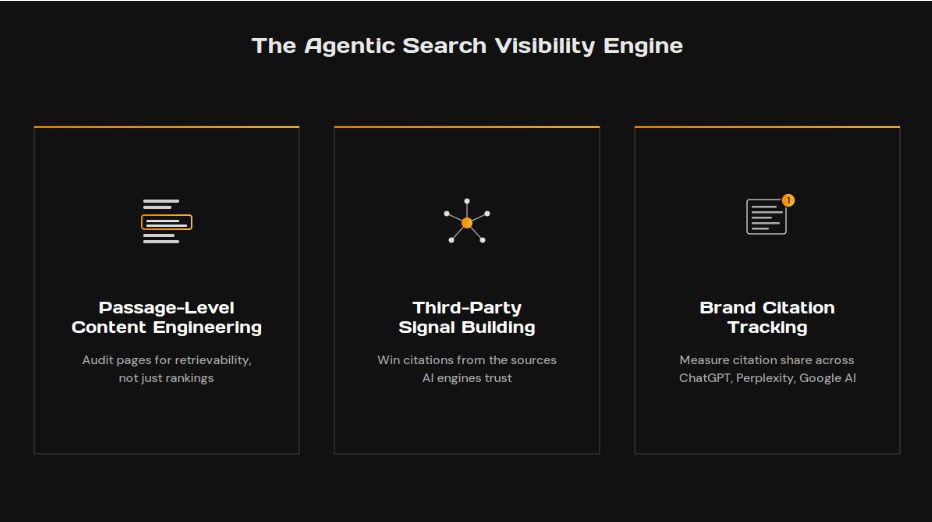
Three workstreams show up on almost every agentic search visibility engagement we run.
The first is passage-level content engineering. We audit existing pages for retrievability, not just rankings. Every section gets reviewed for whether it answers a specific question cleanly and whether it can stand alone if pulled out as a passage. Pages with clean answer paragraphs near the top get cited at materially higher rates than pages that bury the answer halfway down.
The second is third-party signal building. AI engines weight earned media heavily. The work is getting the brand mentioned, quoted, or linked from the sources AI engines lean on most: Wikipedia, Reddit, industry publications, G2-style review sites. That looks more like digital PR than traditional SEO, since it is.
The third is brand citation tracking. SEO tracks rankings. AEO and GEO track mentions, citations, and the queries that triggered them across ChatGPT, Perplexity, Google AI Mode, and Claude. Different tools, different dashboards. “Did the brand show up in the AI answer?” replaces “what position did the page rank?”
These three workstreams form the core of our Good SEO™ approach. Same source content gets engineered for retrievability, distributed through earned channels, and measured against citation share. Built once, distributed everywhere, cited in the answer surfaces your buyers actually use.
One Engagement Where This Approach Moved Revenue
The math is real when the work happens.
For a3PL eCommerce client, we ran a 12-month engagement built around the agentic RAG playbook before the term was standardized. The work split three ways. An outreach-led link strategy ran at roughly 50 backlinks per month, targeting publications AI engines lean on for shipping and fulfillment queries. The content team rewrote category and resource pages for passage-level retrieval, with answer paragraphs near the top and topical depth on niche fulfillment sub-queries. A weekly citation report tracked which queries cited the brand against which queries didn’t.
The result: 8,000+ high-difficulty keywords on page one of Google, organic traffic from 40,000 to 180,000 monthly visits, and total revenue 3x the prior year. The link velocity built the brand into AI answers about fulfillment alongside the long-form content motion. Same playbook a competitor could read about in any agentic RAG explainer. Different outcome since the budget supported the workstreams that actually win each of the five stages.
Working With AlchemyLeads on Agentic Search Visibility
Agentic RAG isn’t a tactic. It’s a structural shift in how AI search picks sources, and it changes which content investments earn citation share.
That’s the work we scope for B2B and eCommerce brands every quarter. No retainers required. Real revenue numbers attached.
Book a strategy call with AlchemyLeads . We’ll map your content against the five-stage gauntlet in 45 minutes.


Suggested

Agentic Resource Discovery: A Practical Walkthrough
Agentic resource discovery is the new standard that tells AI agents what your website can do for them. Most sites have no answer yet. They are invisible to the agents that will soon book, buy, and research for real customers. Here is the problem. Search is moving from people typing queries to agents acting on their behalf. If an agent
July 6, 2026
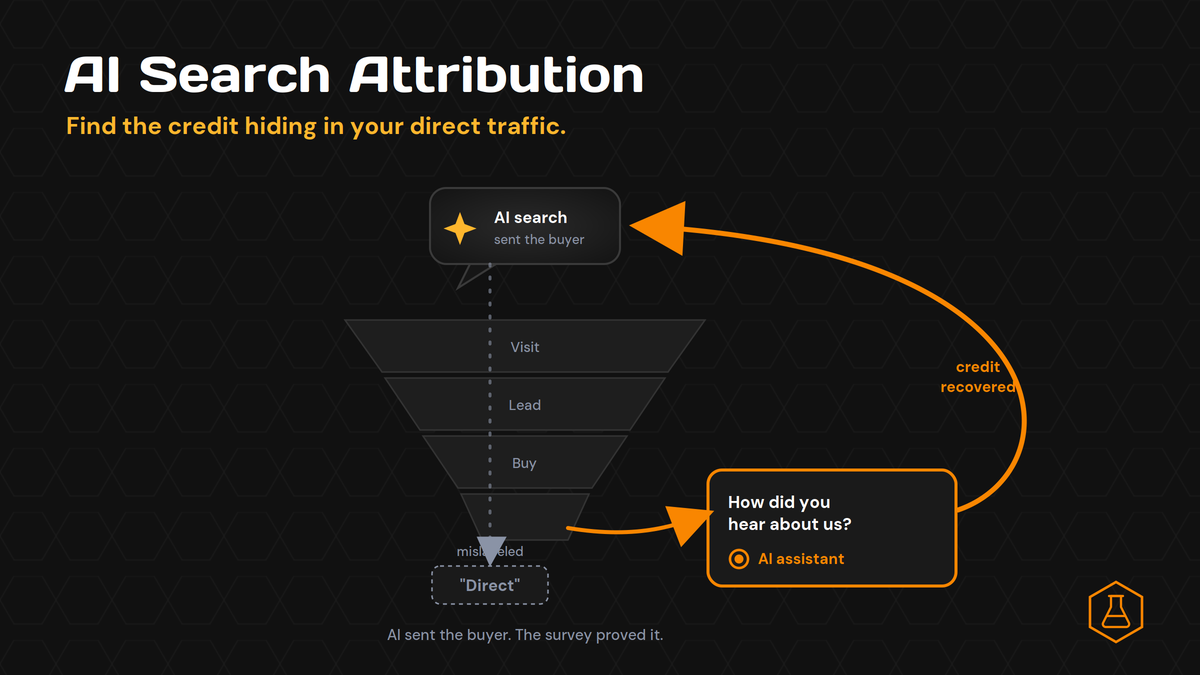
How to Solve the AI Search Attribution Funnel
Your AI search work is paying off. People are finding you in ChatGPT and Perplexity, your brand shows up in the answers, and demand feels warmer than it did last year. Then you open your analytics. The channel that grew is “Direct.” The report says AI sent you almost nothing. That gap is not a traffic problem. It is an
July 2, 2026
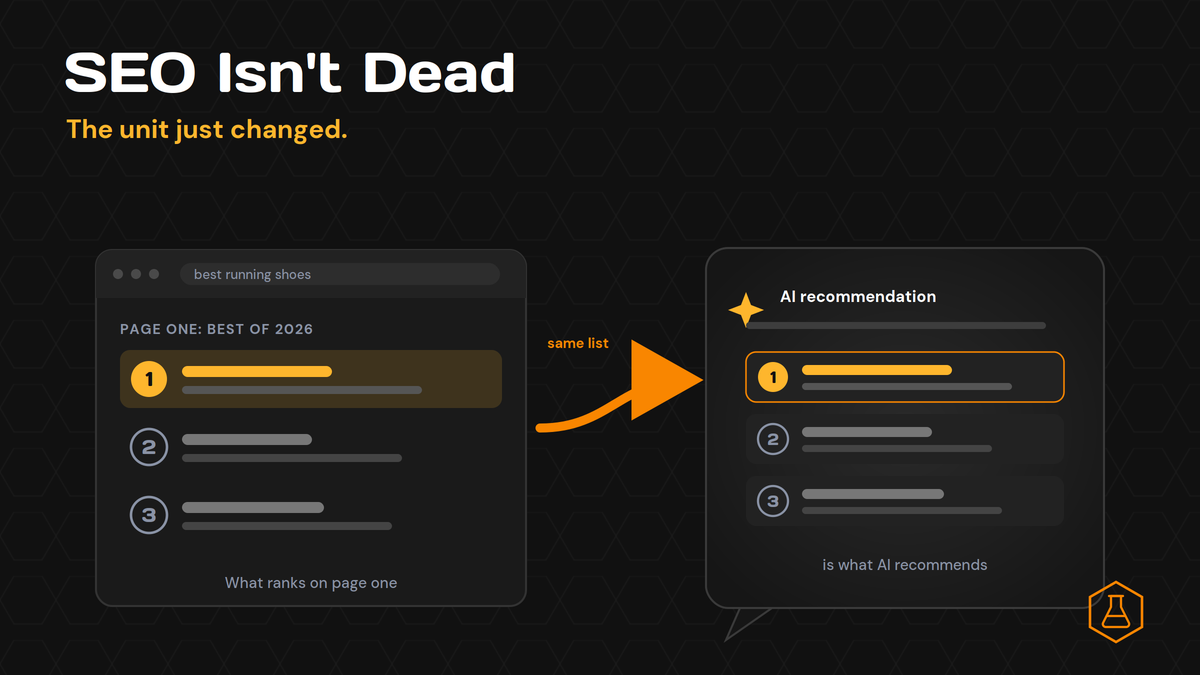
SEO Isn’t Dead. The Unit Just Changed.
Every quarter someone declares SEO dead. This year AI search is holding the knife. The logic sounds clean: if ChatGPT and Perplexity answer the question, nobody clicks a blue link, so why rank at all? We wanted a real answer, not a hot take. So we ran the test. We sent 8 buyer-style “best tool” questions through Perplexity and logged
June 29, 2026
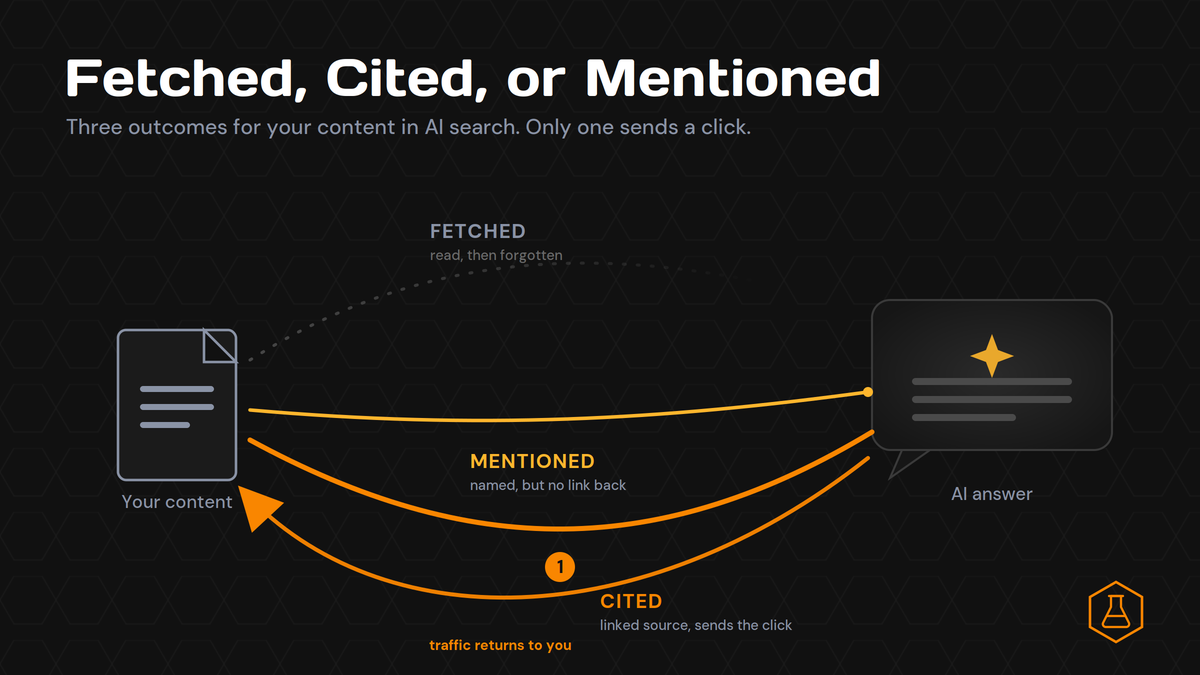
Fetched, Cited, or Mentioned: The 3 Ways AI Uses Your Content
You ran the test every marketer runs now. You asked ChatGPT about your category, watched your brand name show up in the answer, and felt good for about ten seconds. Then you checked your traffic. Nothing moved. Here is the part nobody explains. A mention is not a citation. And a citation is not the same as the page that
June 26, 2026

Open Knowledge Format: What It Means for SEO
Google just shipped the Open Knowledge Format, and the SEO world is split on what to do with it. Some say it’s the next big thing for AI search. Others say it has nothing to do with your rankings. Both camps are partly right. Here’s the short version. Open Knowledge Format (OKF) is a way to package your business knowledge so
June 23, 2026
Contact us
We value your privacy and won't share your email with others.
We'll only contact you with curated content.