AI search picks sources differently now. The old model was simple. Be retrievable. Make sure crawlers can find your content, build authority through links, structure your pages so they rank. That model still works. It’s no longer the only one operating.
A second layer has shipped on top. AI agents can call your site directly, the same way a developer would call an API. The protocol is named WebMCP, and it just made the jump from developer experiment to SEO concern. Suganthan Mohanadasan’s implementation guide brought it into the conversation. Google has a competing version in Chrome’s W3C origin trial. Anthropic ships native support in Claude.
If your AI search strategy still optimizes only for retrieval, you’re working a smaller surface than your buyers are using. This piece walks through what WebMCP is, why it changes what SEO optimizes for, and what we learned shipping it on alchemyleads.com this week.
What WebMCP Actually Is
WebMCP stands for Web Model Context Protocol. The base MCP protocol came from Anthropic and standardizes how AI clients talk to external tools. WebMCP extends that to the browser. The site owner adds a small JavaScript loader, registers tools through that loader, and an AI agent paired to the user’s browser can invoke those tools the way it would invoke any other MCP server.
Three components have to be in place. The first is a script on your site that defines the tools and what they return. The second is a local bridge running on the user’s machine that brokers messages between the browser and the AI client. The third is a paired widget, usually a small floating button, where the user grants the agent permission to talk to your tools.
Two versions of the protocol are in play. The open source jasonjmcghee/WebMCP project shipped first and is what most published implementations use today. The formal W3C draft, a joint Google and Microsoft proposal developed in the Web Machine Learning Community Group, entered Chrome’s origin trial in version 149 and operates on similar principles with different transport. Both solve the same problem. Most sites that have shipped this week chose the open source version since it’s already in production, working with the AI clients people actually use, and easy to swap for the formal version later as the W3C draft matures.
Why This Matters for SEO
Three things change structurally when an agent can call your tools instead of scraping your pages.
The first is structured, brand-controlled data delivery. When an agent invokes a tool you wrote, it gets back exactly the data you defined in exactly the format you specified. No HTML parsing fragility. No agent misreading a case study and quoting 300 percent when the result was 3x. You write the payload, you write the framing, you write which numbers are exposed. The output is deterministic in a way scraped content never is.
The second is conversion bypass. A buyer asking Claude or Perplexity to recommend an SEO agency for B2B SaaS can pull your case study data, your service positioning, and your booking URL directly into the agent’s reply if your site is wired up. The buyer never visits your site. The conversion happens inside the answer. That’s a structurally different funnel from traditional organic, and it’s the same shift we wrote about in the agentic RAG explainer.
The third is the meta-level shift. Your tool descriptions are now ranking copy. They’re the strings an agent reads when picking between your tools and a competitor’s. Same role meta descriptions have played for click-through rate in classic SEO. The audience is an LLM. The decision is “call this function” rather than “click this link.” Generic descriptions lose to specific ones.
How We Shipped WebMCP on alchemyleads.com
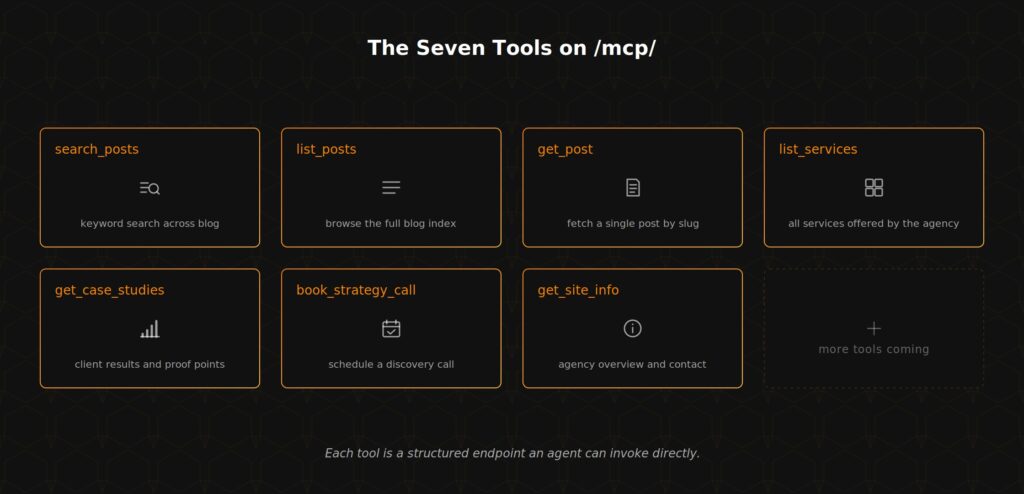
This week we shipped WebMCP on our own site. The /mcp/ page registers seven tools an agent can invoke against AlchemyLeads:
- search_posts (keyword search across the blog)
- list_posts (full post inventory pulled from the sitemap)
- get_post (fetch the full text of a single post)
- list_services (the AlchemyLeads service offerings)
- get_case_studies (structured client outcomes)
- book_strategy_call (the booking URL with framing)
- get_site_info (positioning, ICP, framework)
The architecture is three layers. A script tag on /mcp/ loads webmcp.js. The script defines the seven tools and their schemas. A user runs a small bridge process locally that brokers the connection. When the user pastes a token into our floating widget, the agent gains access to all seven tools.
Three real-world failures showed up that aren’t in any tutorial.
| Issue | What Caused It | Fix |
| WordPress mangled the JavaScript | The wpautop filter wraps page content in paragraph tags at render time, so every blank line in our registration script became a paragraph close mid-function | Move scripts into a WPCode HTML Snippet, which bypasses wpautop entirely |
| Conditional logic silently failed | WPCode Lite’s “Page URL” condition matches the full URL, not the path, so “Is /mcp/” never matched https://alchemyleads.com/mcp/ | Switch the operator to “Contains” or self-gate inside the JavaScript with a window.location.pathname check |
| Config file in an undocumented path | MSIX-packaged Claude Desktop sandboxes config away from the documented %APPDATA%\Claude\claude_desktop_config.json | Settings, Developer, Edit Config opens the correct sandboxed file in the right place |

The connection chain itself is brittle. Browser tab open, bridge running, fresh token, widget connected, AI client restarted in the right order. Five conditions have to align. The widget also drops the connection after about five minutes of inactivity, which means production usage needs a persistent session or an automated re-pairing flow. We got the integration working in roughly four hours of debugging. A first-time implementer should plan for half a day.
The Discovery Problem Nobody Has Solved
The gating constraint on WebMCP isn’t the technology. It’s discovery.
An agent has to know your /mcp/ endpoint exists before it can invoke your tools. Today most agents don’t crawl for these endpoints. They rely on the user telling them. “Use the tools at alchemyleads.com/mcp/” is the only reliable trigger. That works for users who already know about you. It doesn’t work for prospects who don’t.
Three discovery options exist today. A footer link from your main site signals the endpoint to any agent that crawls your home page. An llms.txt entry at your root listing /mcp/ as an available surface picks up agents reading that file. And a handful of independent directories are starting to form where site owners can list their MCP endpoints publicly. Digital PR accelerates inclusion since the same earned-media sources that feed AI training data are the ones building these directories.
A standardized discovery layer is the missing piece. Until it exists, WebMCP is an early-mover play. The site owners who ship now get into the directories first. The site owners who wait get in later.
Be Retrievable vs Be Callable
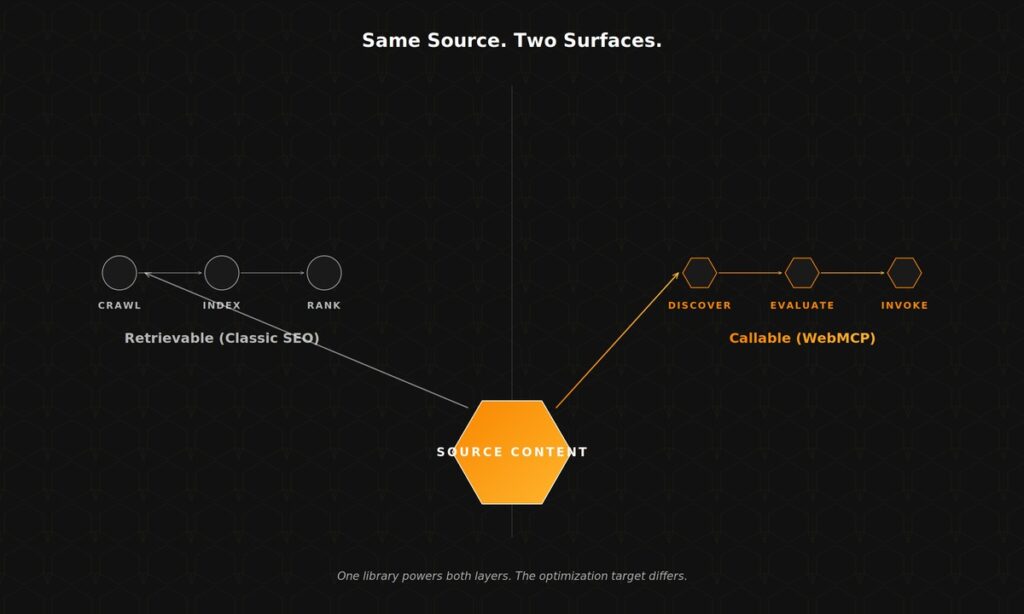
SEO has always been about being retrievable. WebMCP introduces a parallel layer where the optimization target shifts from getting found to getting invoked. Both layers matter, and the same source content powers both.
| Dimension | Retrievable (Classic SEO) | Callable (WebMCP) |
| Discovery mechanism | Crawlers find your content | Agents invoke your tools |
| Optimization target | Show up when someone searches | Be the tool the agent picks |
| Conversion copy | Meta title and description | Tool name and description |
| Failure mode | Outranked by a competitor | Generic description loses to a specific one |
| Source content | Blog, case studies, service pages | Same blog, case studies, service pages |
The last row is the punchline. Your case studies feed your blog (retrievable) and your get_case_studies tool (callable). Your service pages rank for category keywords (retrievable) and feed list_services for an agent comparing options (callable). One library, two surfaces. GEO handles the retrievable layer. WebMCP handles the callable one.
Tool descriptions do the work meta descriptions used to do. They’re conversion copy aimed at an LLM. Specific beats generic. Outcome-focused beats feature-focused. The agency writing “Return three years of B2B case study outcomes with revenue figures” beats the one writing “Return our case studies.” That’s the same discipline behind strong AEO work, pointed at a different audience.
When to Ship WebMCP and When to Wait

WebMCP isn’t right for every site this quarter. The honest decision framework comes down to whether your buyers are already using AI for research, what kind of data your brand has to expose, and whether your team can maintain the integration.
| Signal | Ship Now | Wait |
| Buyer behavior | B2B or complex evaluation, where buyers ask Claude, Perplexity, or ChatGPT for recommendations | DTC or mass market, where browsing the product is the experience |
| Brand strengths | Differentiated positioning, real case studies, structured data worth exposing | Visual, design-led, experiential, hard to compress into a JSON payload |
| Engineering capacity | In-house developer or a budget to outsource setup and maintenance | No technical resource to own the integration past launch |
| Conversion path | Booking flow, demo request, structured pricing, gated calculator | “See the product to convert” with no booking-style endpoint |
The middle path exists. A brand can ship a minimal WebMCP surface that exposes only site info, a service list, and a booking URL. Three tools, half a day of engineering, no commitment to maintain a full content-search layer. That gets the brand into the early directories and on the radar of agents that crawl for /mcp/ endpoints without overcommitting the calendar. The full integration with case study data and content search comes later, once the protocol stabilizes and discovery layers form.
The biggest mistake is treating WebMCP as a marketing tactic. It’s infrastructure. The work of writing good tool descriptions, exposing the right data, and maintaining the integration across protocol changes is closer to API engineering than to content production. Budget accordingly.
How AlchemyLeads Wires WebMCP Into Revenue First SEO
We approach AI search visibility as one integrated workstream, not a stack of disconnected tactics. The framework we use with clients is Revenue First SEO, formalized in our Good SEO™ approach.
Same source content gets engineered for retrievability through GEO and AEO work. The blog earns citations across ChatGPT, Perplexity, Google AI Mode, and Claude. Service pages get tuned for passage-level extraction. Topical maps build the breadth that planner stages of agentic search need to surface your category in the first place.
WebMCP is the callable layer on top. Same data, same brand voice, exposed through a structured tool surface. The seven tools on our /mcp/ page aren’t an isolated project. They aggregate the case studies our content team writes, the service positioning the strategy team owns, and the booking flow conversion runs through. One source of truth, three surfaces.
When we scope an engagement, WebMCP setup is a one-off workstream that fits under No-Retainer SEO. No twelve-month commitment to test whether the integration is worth it. The pilot we ran on our own site this week takes roughly half a day for a developer who has done it before. The maintenance is light once it’s live.
If you’re scoping for an agency relationship that takes AI search seriously, ask whether they’ve shipped WebMCP themselves. The conversation goes differently with a team that has lived through the failure modes and built the integration, not just read about it.
Working With AlchemyLeads on AI Search Visibility
WebMCP isn’t a tactic. It’s the new layer of AI search visibility, and it changes which content investments earn citation share in 2026 and beyond.
That’s the work we scope for B2B and eCommerce brands every quarter. No retainers required. Real revenue numbers attached.
Book a strategy call with AlchemyLeads. We’ll map your content against the retrievable layer


Suggested
Fetched, Cited, or Mentioned: The 3 Ways AI Uses Your Content
You ran the test every marketer runs now. You asked ChatGPT about your category, watched your brand name show up in the answer, and felt good for about ten seconds. Then you checked your traffic. Nothing moved. Here is the part nobody explains. A mention is not a citation. And a citation is not the same as the page that
June 26, 2026

Open Knowledge Format: What It Means for SEO
Google just shipped the Open Knowledge Format, and the SEO world is split on what to do with it. Some say it’s the next big thing for AI search. Others say it has nothing to do with your rankings. Both camps are partly right. Here’s the short version. Open Knowledge Format (OKF) is a way to package your business knowledge so
June 23, 2026
Entity-Based SEO for AI Search: A Live Build Breakdown
Your page ranks number one. You ask ChatGPT the same question, and your brand never comes up. Entity-based SEO for AI search is the work that closes that gap. AI engines don’t sort ten blue links. They pull facts, attach them to entities, and cite the sources they trust to define those entities. If a model can’t tell what your brand is,
June 22, 2026

WebMCP for SEO: What It Means When AI Agents Call Your Site
AI search picks sources differently now. The old model was simple. Be retrievable. Make sure crawlers can find your content, build authority through links, structure your pages so they rank. That model still works. It’s no longer the only one operating. A second layer has shipped on top. AI agents can call your site directly, the same way a developer
May 27, 2026

Google Search Console Regex: The Revenue First Playbook
Google Search Console regex isn’t just a syntax puzzle. Get the 6 patterns that earn their keep and the revenue moves they trigger.
May 27, 2026
Contact us
We value your privacy and won't share your email with others.
We'll only contact you with curated content.